CMS. Anyone in the web biz knows what this stands for: “Content Management System.” The problem is, these systems often don’t properly or efficiently manage content. As a result, CMS has become the new dirty word when it comes to solutions for providing content on the web – or anywhere else for that matter.
The Evolution
They started off innocently enough. Blogs are probably the earliest examples of CMS systems that were available to the masses, and at that time content on the web was primarily synonymous with web pages and media assets (images, video, audio). Datastores were mostly restricted to traditional RDBMS systems with SQL interactions. Referencing other pieces of content was restricted to direct links, pingbacks, etc.
As website requirements expanded over the years, CMS systems evolved to meet the growing needs and platforms emerging into the market, datastores that were becoming available (NoSQL, distributed solutions), and scalable hosting solutions. However, the assumption remained that all content is being served up to web browsers (albeit running on different devices like tablets and phones). As such, these systems began to evolve into what are actually web content management systems (WCMS) which are optimized for managing web content, HTML markup, and publishing workflow. However, for marketing continuity these systems have maintained their CMS labeling going forward, when in actuality these systems don’t manage content – they manage web pages.
The Challenge
Having worked in the large-scale CMS (WCMS?) market for several years, I’ve observed the evolving trends in requirements for content management and consumption ranging across several different industries. More and more you see requirements for systems where strong relational references and integrity are required, along with increasing integration with external systems. Semantic metadata is the newest layer attached to content, regardless of its type (media, text, etc), and is almost required to maintain any form of referential integrity or provide context for assets.
That being said, most existing CMS solutions are still trying to back new functionality into page-centric content stores instead of addressing semantics of the content as a first-class requirement in systems design. The datastores themselves are typically still based on some tabular backend, either a traditional RDBMS or document-store NoSQL solution where relationships have to be explicitly mapped into the system via increasingly complex referential mechanisms which are often fragile and fraught with peril. The presentation and administrative access points are also still tied almost exclusively to web-based interfaces, with partial attempts to expose the content via RESTful services – which typically return HTML markup from the baked-in presentation layer or proprietary JSON that simply dumps the complex data structure from the RDBMS or document store for the requested resource. Hence the need for more advanced query systems such as GraphQL to manage what you need and when.
The Proposal
So we have legacy systems that really don’t address the current requirements for content management, namely semantic context, referential integrity, and the ability to (relatively) easily integrate assets from external systems. What are some ways we could address these issues?
Make semantics a priority.
If a system is designed from the beginning to leverage the state of the art for semantic context, it becomes a legitimate component in your information architecture and not an afterthought tacked on to pass SEO test suites and allow stakeholders to check off a box in the UAT spreadsheet. Schema.org is an open web semantic standard backed by a consortium of large search providers and content providers which provides an extensible hierarchy of content concepts (it’s an ontology after all). If you ever use the Google Knowledge Graph API, the returned data is most likely tagged with a Schema.org type. Many DBPedia entries are as well.
Content organized and structured with Schema.org (or one of its brethren) semantics not only allow richer search experiences, but referential integrity that the semantic web has long promised and so far not delivered on. Your content should never be just a “post” or “page” with a few random tags, but should instead be a well-structured piece of content with references to related content and some semblance of concept and context baked in.
Free your content.
Your UI/UX is not your content; quit trying to make your content your UI/UX. Content with embedded markup is not portable across disparate systems, and can only be rendered properly by certain clients. Embedding markup also loses the semantics of the related content (is that URL an image, social link, or published document?) which makes relating independent content pieces a challenge at best (have you ever had to “scrape” a web page into a structured content type in a CMS before?).
How to accomplish this? Get away from the idea that every piece of content is a web page, and instead use structured data. This means if you need an image, add an image component. Table? Add one of those components as well (but as structured data, not Markdown or HTML). Layout structure? Your content should be able to reside in a layout, but not contain it; layout is a function of the presentation layer, not what you’re trying to store or convey. Every component of your content should have its own context, and live within a well-structured parent.
Knowledge does not have a primary key.
Current content systems generally use freeform tagging, maybe a controlled taxonomy, and other key-related relational systems (with massive SQL joins) in an attempt to tie content together. However, content should be viewed as a knowledge graph – aggregated, linked, and structured knowledge. As such, knowledge doesn’t have a “primary key” and can be quite messy. I challenge you to find one used to tie content together in a system like Wikipedia or DBPedia.
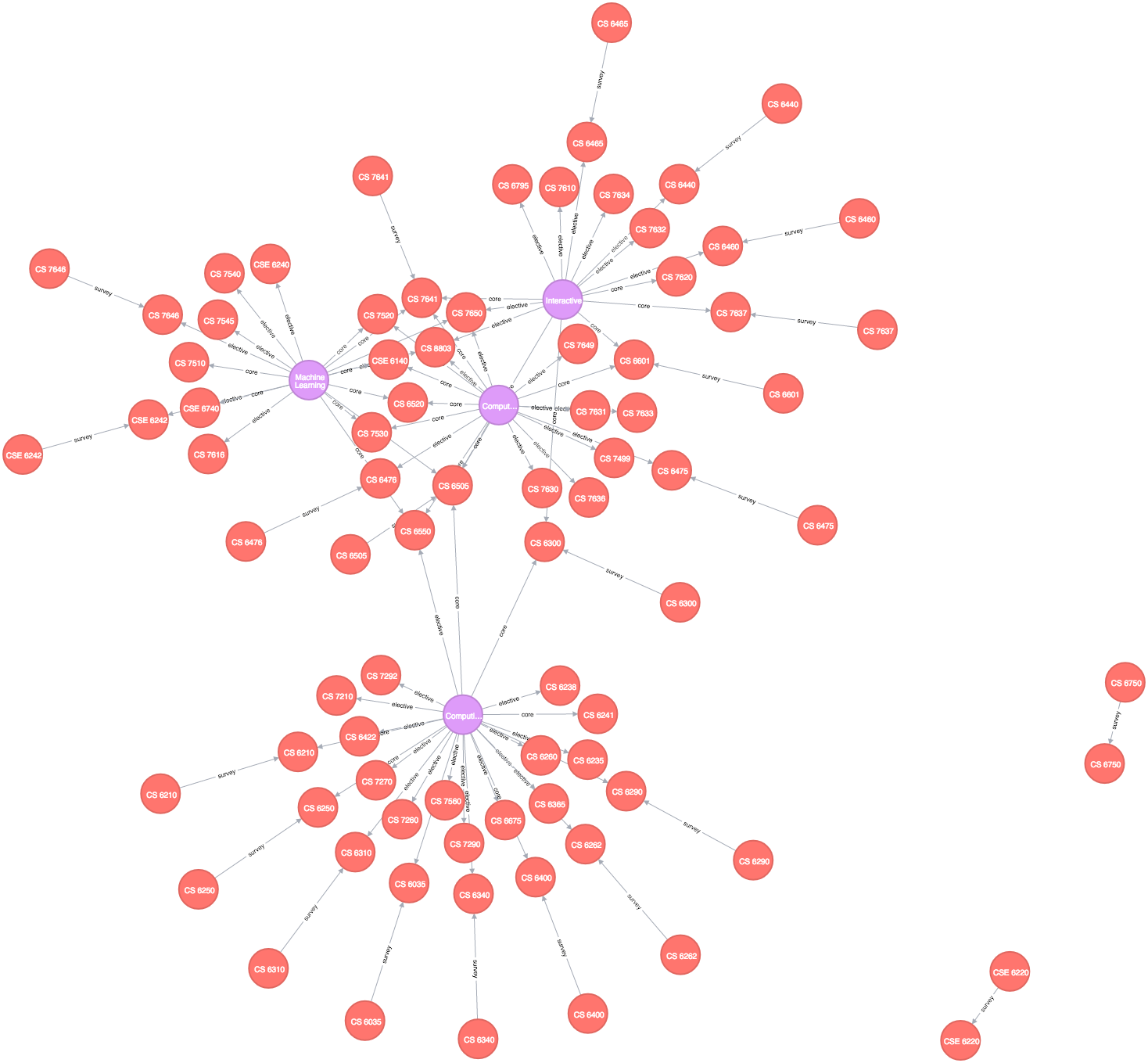
OMSCS specializations, courses, and course surveys
The sample knowledge graph above is for the very small domain of Georgia Tech’s OMSCS program (courses, course surveys, and specializations) I created for a class project. Notice how many pieces of content (vertices/nodes in graph structures) have multiple relationships (edges) and many are labeled and directional (e.g. this “belongs to” that, this “reviews” that, etc.) so that we can model not only the content but how it relates to other content. When you hear people talk about the “semantic web” this is the kind of web they are discussing, not a SQL database with hundreds of tables and convoluted joins. Content should live in a graph structure where anything can be linked to anything else, which encourages knowledge discovery and relatability. When you look at traditional content such as books, papers, presentations, etc you don’t see content tabulated, you see it linked (e.g. citations, references, footnotes, acknowledgements). Why should digital content be any different? (And no, simply dropping a hyperlink in the middle of your content doesn’t solve the problem, it actually exacerbates it.)
The Conclusion
The WCMS has its place – websites need to be built, and HTML+CSS will always be around to customize look and feel of web-based content. However, I think the community need to do two things. First, they need to differentiate between a CMS and WCMS where the former manages universal, structured content with semantics, context and referential data as first class architectural goals. Second, instead of expending effort on trying to back semantics, relationships, and context into a traditional WCMS, let’s work more on building true CMS solutions and lightweight presentation layers to work with them. That way content management can evolve independently of presentation, and presentation can evolve without being bound to legacy content with embedded presentation markup.