You’ve spent days (weeks?) applying data science best practices to your shiny new dataset to make sure it is balanced, unbiased, privacy oriented, and representative of your target inference goals. You have also spent nearly as much (or more) time experimenting with neural network models in order to find that perfect balance between accuracy and generalization. Now you want to make your model available for use, either internally or to the public. How do you go about doing so?
The subfield of machine learning operations (MLOps) is a relatively new spinoff from DataOps and DevOps, in a way a merger of the best practices of both. While MLOps is primarily focused on production-scale ML deployments, there are often simpler MLOps workflows that involve models embedded in smaller systems, or even on edge devices. To provide flexibility in all these scenarios, the Open Neural Network Exchange (ONNX) (ONNX| Home, n.d.) was developed to allow interoperability between ML frameworks and optimized runtimes for various target environments. One such runtime that we’ll explore in this post is the Microsoft ONNX Runtime (ONNX Runtime | Home, n.d.).
Why The Microsoft ONNX Runtime?
In a nutshell – flexibility. Many people see “Microsoft” as a Windows-only, Azure-only software vendor, which might have been true many years ago. However, with the open sourcing of .Net Core and the advent of Visual Studio Code, Microsoft’s strategy has begun to shift towards more cross-platform support and code transparency in many of its developer products. The ONNX Runtime is no exception, as seen in Figure 1.

Beyond cross-platform support, Microsoft is also one of the ONNX Consortium members and a major supporter of the standard, even when it was only a Linux Foundation incubator project. Additionally, they have provided optimization tooling for non-Microsoft frameworks (like DeepSpeed for PyTorch and HuggingFace) (“DeepSpeed,” n.d.) which indicates that they are committed to promoting the use of ML open standards and are not betting on any one ML movement. Microsoft’s final pièce de résistance is the ONNX Model Zoo that provides a collection of SOTA and seminal pretrained DL models, exported in ONNX for use by anyone, anywhere (ONNX Model Zoo, n.d.).
All things considered, it’s a great platform to experiment with for production inference deployment, as well as smaller-scale solutions, and fairly easy to use IMHO.
Leveraging the runtime
For our example, I’m going to use a language ecosystem that is pervasive in the business world, as well in many production deployment environments – which also happens to have relatively weak representation when it comes to machine learning – Java. Sure, there are DL4J, SparkML, and a few other rarified and/or challenging clustering tools in the Java ecosystem, but not many simple mechanisms to deploy an externally-trained model in a Java environment short of trying to bridge Python and Java. The ONNX Runtime fills this need.
Code
Without getting into the weeds of creating a new Java Gradle project, configuring the dependencies, and stubbing out an application class, we’re instead going to focus on the actual moving parts of the ONNX Runtime (ORT).
Most ML inference workflows at a 10,000-foot view look like this:
- Load and initialize a pre-trained model
- Receive raw data to run inference on
- Preprocess the raw data into the format expected by the model (one or more input layers, dimensions, value ranges, etc ad nauseum)
- Perform inference on the data using the model
- Report results
Since receiving raw data and reporting results is system-specific, let’s just focus on the other aspects of this workflow and how they map into the ONNX Runtime.
Our example is going to implement a simple command-line tool for classifying an image from the classic MNIST handwritten digits dataset. The model we’re going to be using comes from the ONNX Model Zoo, and has the following architecture:
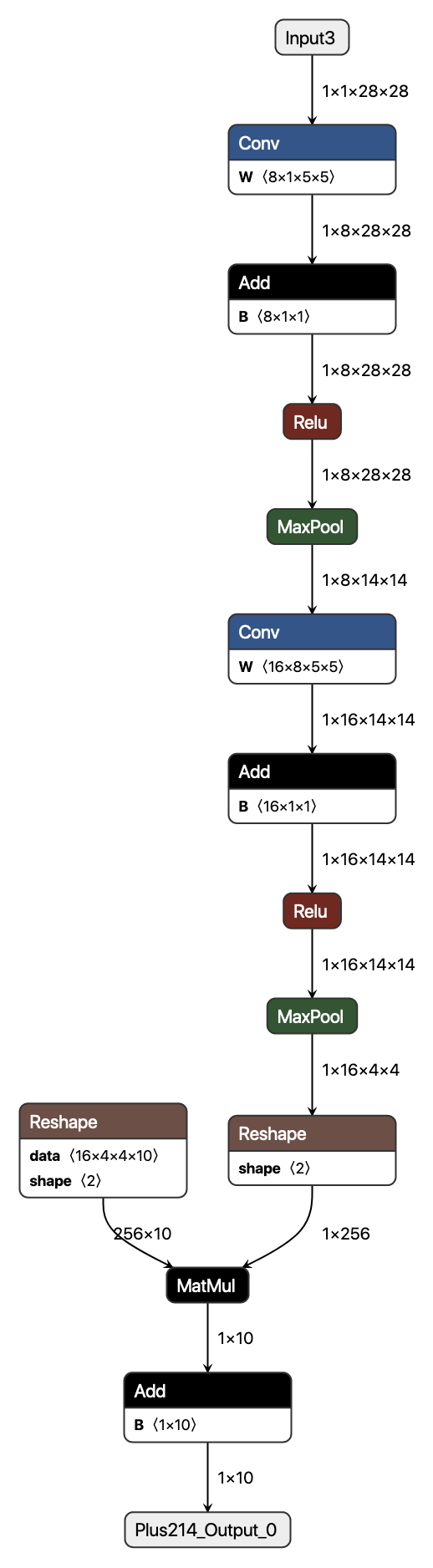
Note the input and output layer names and dimensions as we’ll be leveraging those in our code.
Load and initialize a pre-trained model
The ORT Java API defines two constructs to access models, the OrtEnvironment and OrtSession. The former provides access to the compute environment provided by the ORT, the latter actually wraps a model for training and/or inference. In our example we’re only interested in inference since we’re loading a pre-trained and exported ONNX model.
// Create environment and session objects for ONNX runtime
OrtEnvironment ort_env = OrtEnvironment.getEnvironment();
OrtSession ort_session = ort_env.createSession(model_path);The model_path parameter is a File object referencing the ONNX model to load; in the demo repo this is bundled as a project resource.
Preprocess the raw data
Preprocessing raw data is not a part of the ORT, but is something that almost always has to be done to perform things like scaling, windowing, normalizing, etc ad nauseum. In our case the MNIST dataset consists of 28×28 pixel images with 8-bit grayscale, each a handwritten digit from 0 to 9 as shown in Figures 3 and 4.

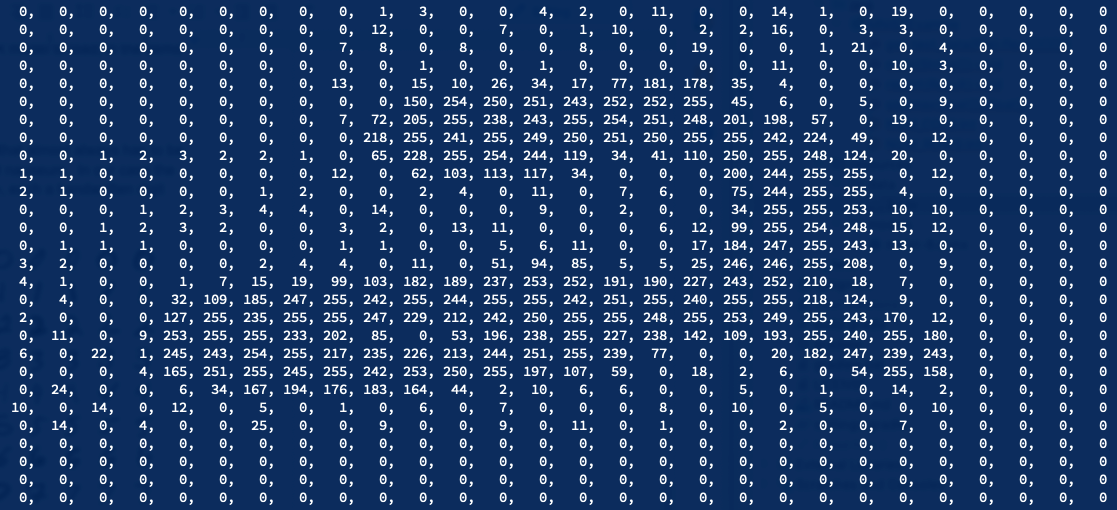
The MNIST ONNX model we are going to use expects the images to be in a rank four tensor (aka array with four dimensions) with the ranks being NCHW where N is number of samples, C is channels of data per pixel, H is the height of the image, and W is the width of the image (this is often referred to as “channels-first” format in the literature). Additionally all values must be between 0.0 and 1.0 inclusive. The demo repo includes a CSV sample for a “2” that can be loaded from the project resources and preprocessed with the following function:
/**
* Load and preprocess the 28x28, 8-bit grayscale MNIST digit
* @param data_file File object to load from; assumed 28x28 CSV file
* @return Preprocessed NCHW input data for the MNIST model
* @throws FileNotFoundException
*/
public static float[][][][] get_test_data(File data_file) throws FileNotFoundException {
String[] strvals;
float [][][][] data = new float[1][1][NUM_ROWS][NUM_COLS];
int row = 0, col = 0;
// Parse our CSV file and preprocess 8-but grayscale values into range of
// [0.0, 1.0]
Scanner sc = new Scanner(data_file);
while (sc.hasNextLine() && row < NUM_ROWS) {
String line = sc.nextLine();
strvals = line.split(",");
for (col = 0; col < NUM_COLS && col < strvals.length; ++col) {
data[0][0][row][col] = Float.parseFloat(strvals[row]);
data[0][0][row][col] /= 255.0;
}
++row;
}
return data;
}Note that the N and C dimensions are one since we have only one sample, and it has only one channel of color information.
Perform inference on the data
Following on the previous two steps, we now pull it all together to actually execute the model in inference mode.
// Create tensor object and map it to the input layer by name
float[][][][] sourceArray = get_test_data(data_file);
OnnxTensor input_tensor = OnnxTensor.createTensor(ort_env, sourceArray);
Map<String, OnnxTensor> inputs = new HashMap<String, OnnxTensor>() {{
put("Input3", input_tensor);
}};
// Execute inference
OrtSession.Result results = ort_session.run(inputs);The object results now holds the inference results from the MNIST model as an iterable/indexable map of result tensors (in the event the model has more than one output layer). That’s it! The application in the demo repo will then print out the result tensor with the softmax operation applied to it, which should look something like this:
Result Plus214_Output_0: TensorInfo(javaType=FLOAT,onnxType=ONNX_TENSOR_ELEMENT_DATA_TYPE_FLOAT,shape=[1, 10])
0: 1.0251797E-6
1: 1.7570814E-5
2: 0.9975446
3: 8.365498E-6
4: 0.0019018119
5: 3.249053E-4
6: 1.8564763E-4
7: 1.2470684E-5
8: 3.4186814E-6
9: 1.9274142E-7Note the zero-based tensor index corresponds to the digit identified, and the index with the highest value is the predicted digit; in this case the model predicted a “2” which is the correct answer.
Conclusion
In this article I have presented the Microsoft ONNX Runtime as an option for production or smaller-scale deployments within or outside the Microsoft ecosystem. We have also seen that it provides a very straightforward interface in Java, which is often neglected for ML solutions that don’t involve complex cluster environments and is often plagued by overly verbose interfaces. In addition to Java, the runtime supports several other languages, operating systems, and compute backends. This is a tool we have been exploring at Veloxiti as an alternative for embedded ML solutions based on the Java ecosystem where Python and C/C++ platforms are fraught with peril when it comes to integration. Between the ONNX specification and the ONNX Runtime, a lot can be accomplished with a very low level of effort.
References
DeepSpeed. (n.d.). Microsoft Research. Retrieved September 13, 2021, from https://www.microsoft.com/en-us/research/project/deepspeed/
ONNX | home. (n.d.). Retrieved September 9, 2021, from https://onnx.ai/
ONNX runtime | home. (n.d.). Retrieved September 9, 2021, from https://onnxruntime.ai/
onnx/models: A collection of pre-trained, state-of-the-art models in the ONNX format. (n.d.). GitHub. Retrieved September 9, 2021, from https://github.com/onnx/models/



